해당 강의를 통해 이해한걸 정리해보면, 객체지향 프로그래밍 언어에서 사용하는 데이터 타입과 데이터베이스에서 사용하는 데이터 타입은 매칭되지 않는다. 그렇기 때문에 데이터베이스에 데이터를 요청하거나 보낼 때 데이터 타입 변환을 해줘야 하는데 이러한 작업은 매우 귀찮은 작업이고 시간이 많이 들어간다 따라서 데이터베이스에서 받은 데이터 타입을 객체지향 언어에서 이해할 수 있는 데이터 타입으로 변환해주는 것이 orm의 역할이라 볼 수 있다.
데퍼를 사용함으로써 얻을 수 있는 이점을 몇가지 알아보면서 마무리 하겠다.
데퍼를 사용하는 이유중 주요한 이유는 빠르다는 것이다. 현재 재직중인 회사에서도 Entity Framework에서 Dapper로 변경을 하였는데 이유는 데이터를 조회시 한번에 가져와야되는 데이터의 수가 증가함에 따라 속도가 느려저서 속도를 개선할 필요성이 필요해서였다.
그리고 코드 라인 수가 감소한다는 이점도 있는Dapper에게 단순히 파라미터와 쿼리문만 주면 되기 때문으로 보인다.
해당 문제를 해커랭크에서 풀어보았습니다. 해당 문제는 해쉬로 푸는 문제지만 이번 문제의 경우 집합이 유리해보여서 set을 사용하였습니다.
해당 문제의 코드는 아래와 같습니다.
def twoStrings(s1, s2):
# Write your code here
s1_set = set()
isSub = False
answer = 'NO'
for str1 in s1:
s1_set.add(str1)
for str2 in s2:
if str2 in s1_set:
answer = 'YES'
break
return answer
해당문제를 풀면서 긴가민가 했던 부분이 있는데 스트링을 포문으로 그냥 range를 안쓰고 문자열로만으로 가능할지 의문이였는데 시도해보니 잘되는 것을 확인할 수 있었습니다.
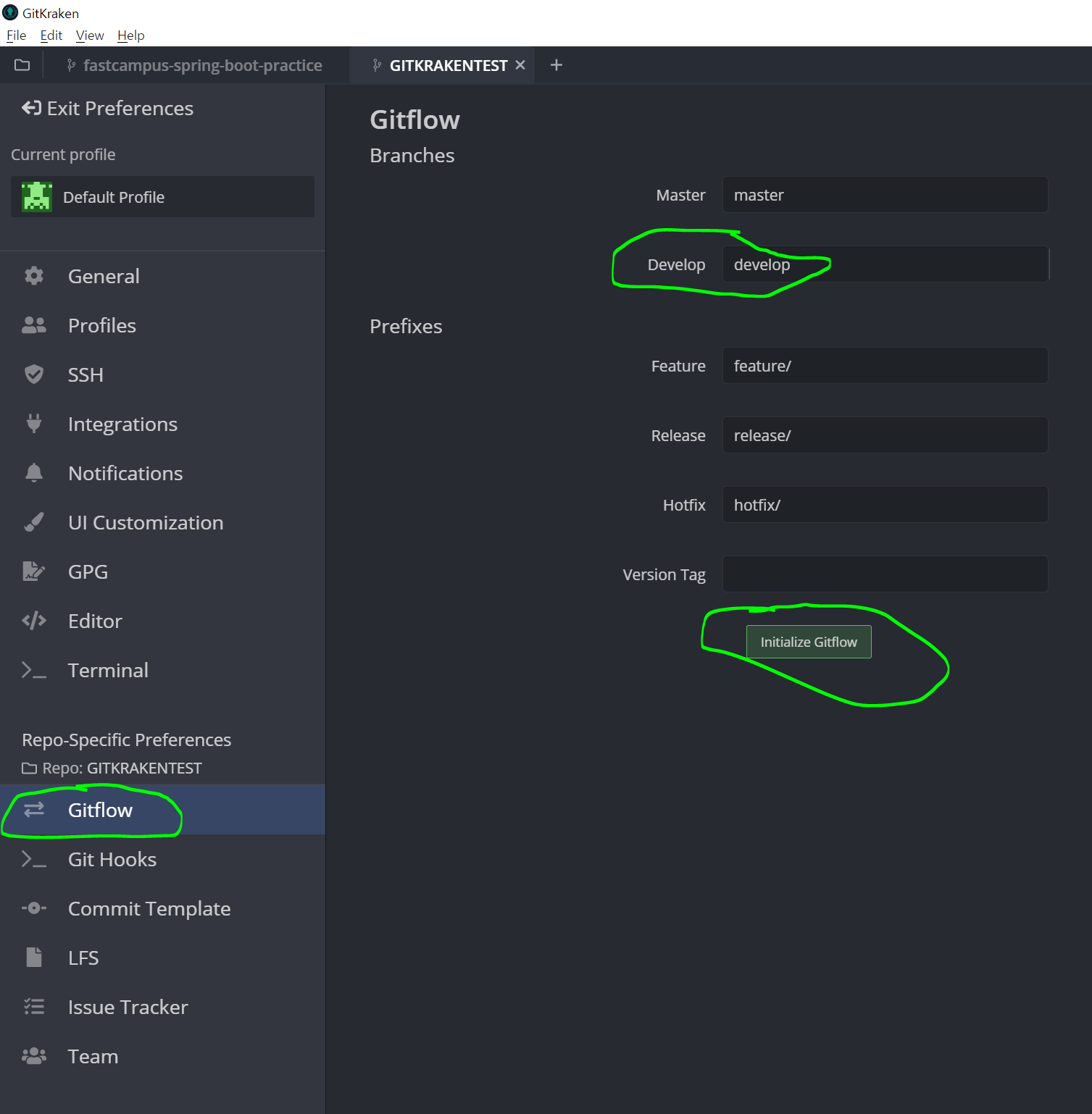
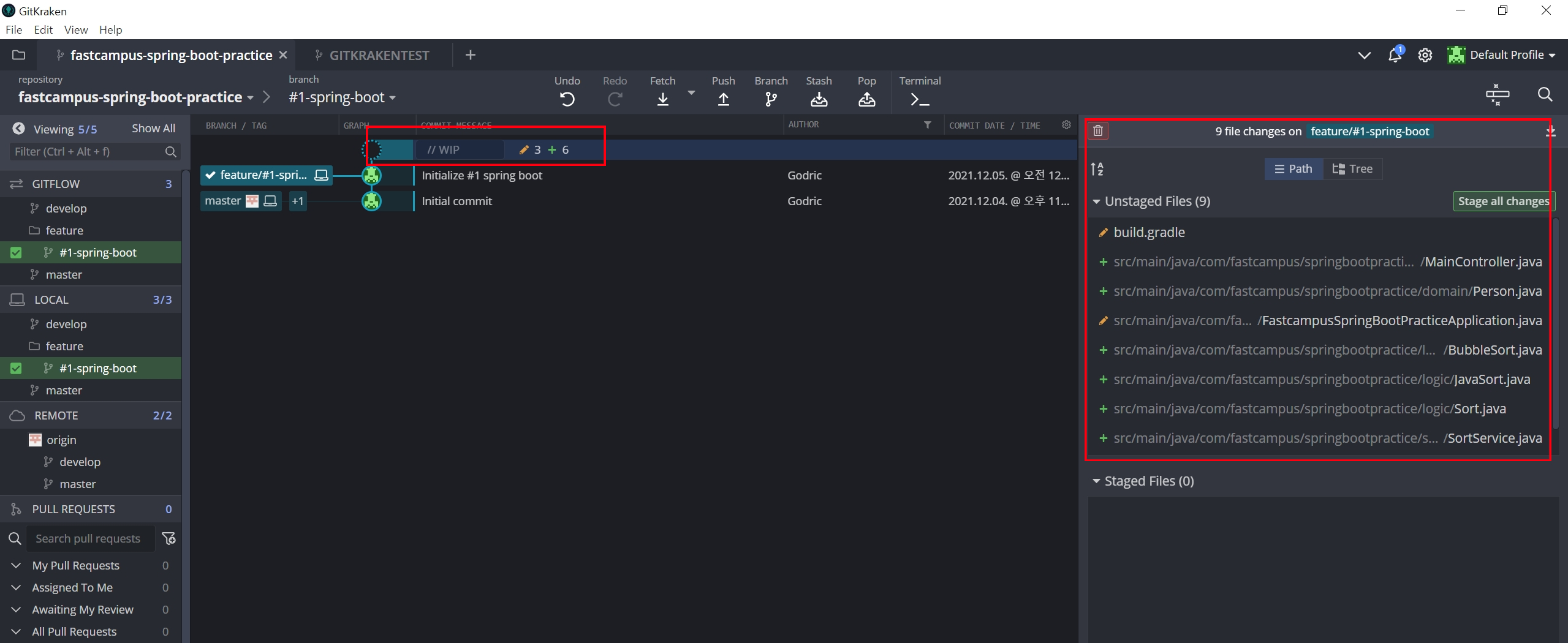
위와 같이 진행하고 있는 작업은 브랜치를 새로 만드는 것입니다. develop 브랜치를 따로 만들어 사용하는 이유는 아직 변경사항 개발이 완료되지는 않았지만 커밋하여 구성원과 코드 공유를 하기 위해서입니다. master 브랜치는 실제로 배포가 준비된 코드만 올라가야되기 때문에 master 브랜치로 현재 개발중인 코드를 커밋하지 않습니다. develop 브랜치를 완성하였으면 master 브랜치와 병합을 하여 master 브랜치에 develop 브랜치를 반영하여 줍니다.
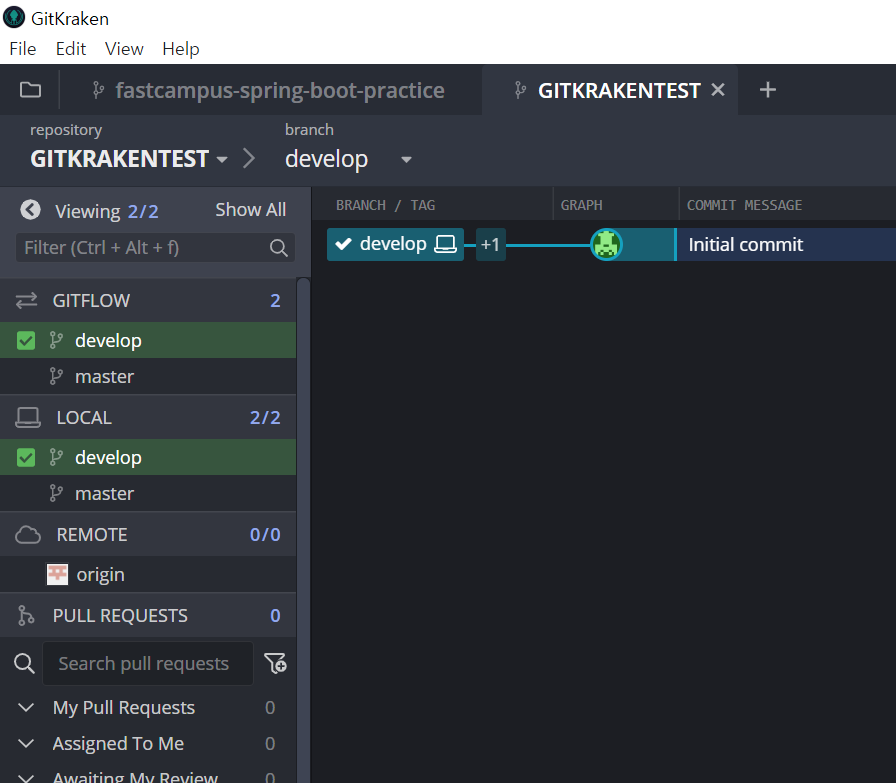
다시 본화면으로 돌아오면 develop 브랜치가 생성된 것을 확인할 수 있습니다. 그럼 develop 브랜치를 더블클릭하면 develop 브랜치로 넘어가서 작업할 수 있습니다.
이제 코드 작업을 한 뒤 깃 크라켄으로 돌아오면
아래와 같이 되는데 우측에서 원하는 파일들만 골라서 커밋을 따로따로 진행할 수도 있습니다.
커밋을 완료하였다면 push를 통해 깃허브에 반영할 수 있습니다. push는 되도록이면 모든 커밋을 한다음 마지막에 하는 것이 좋은데 가끔 실수하여 커밋을 되돌려야 할 때가 있습니다. 그때 push가 되지 않은 상황이라면 undo 기능을 통해 되돌릴 수 있습니다.
이제 developer 브랜치에서 개발이 완료되었으면 master 브랜치와 병합해주도록 합시다.
kendoGrid를 위해 사용되는 schema와 schema는 어떤 기능이 있는지 살펴보겠습니다.
schema
서버에서 보낸 응답을 파싱 하여 KendoGrid에 어떻게 데이터를 보여줄지 그리고 편집은 어떻게 할지 알려 줍니다.
schema.groups
그룹을 포함하는 서버 응답의 필드 응답에서 그룹을 반환하기 위해 호출되는 함수로 설정할 수 있습니다.
해당 옵션은 serverGrouping option에 true 값을 할당해야 사용할 수 있습니다.
위 내용은 공식 문서를 번역한 설명입니다. 내용이 조금 어려우니 아래 예시를 참조해주세요
직접 사용한 예를 보여드리겠습니다.
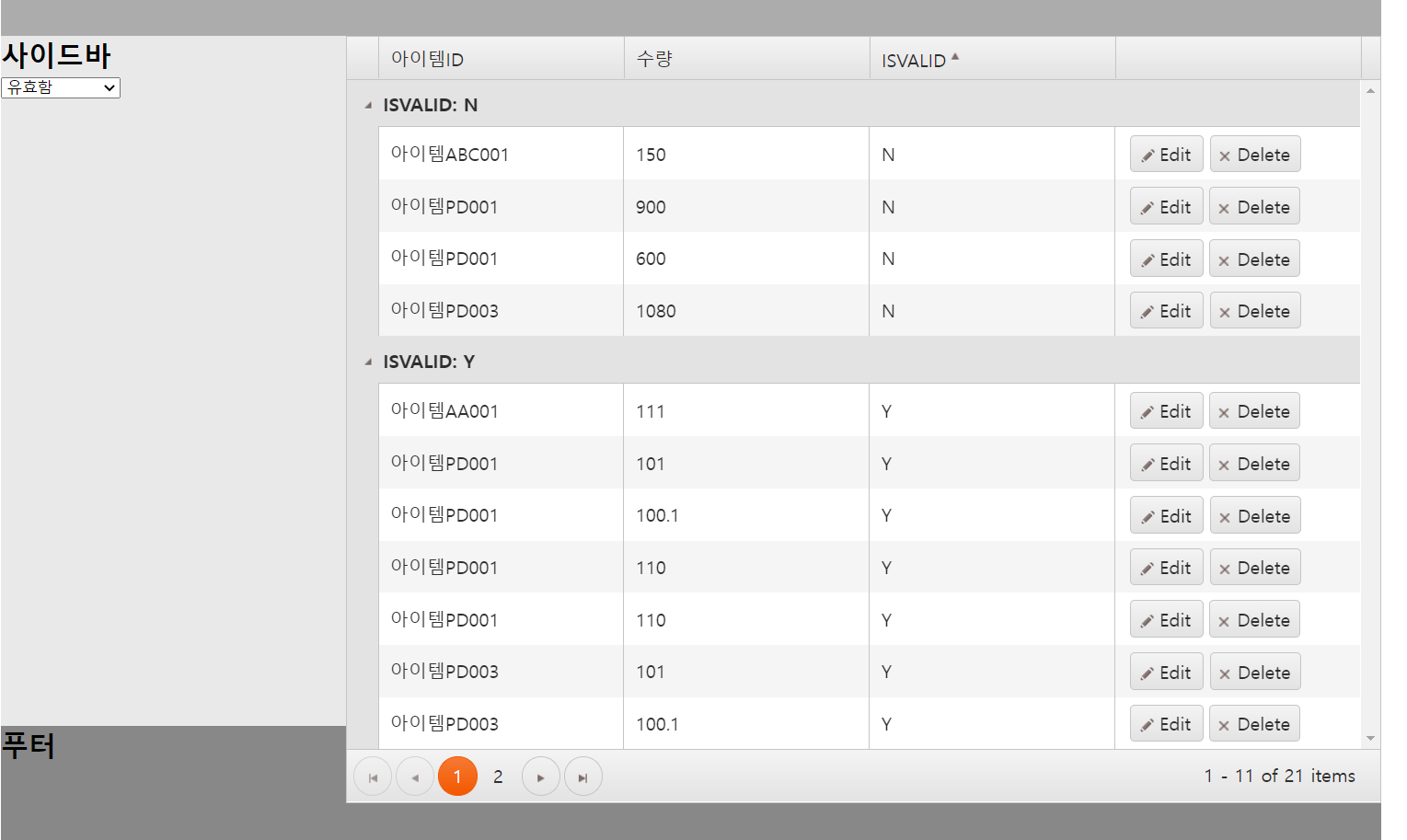
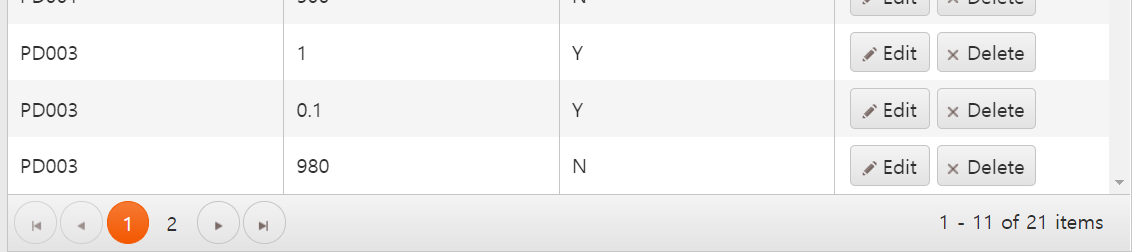
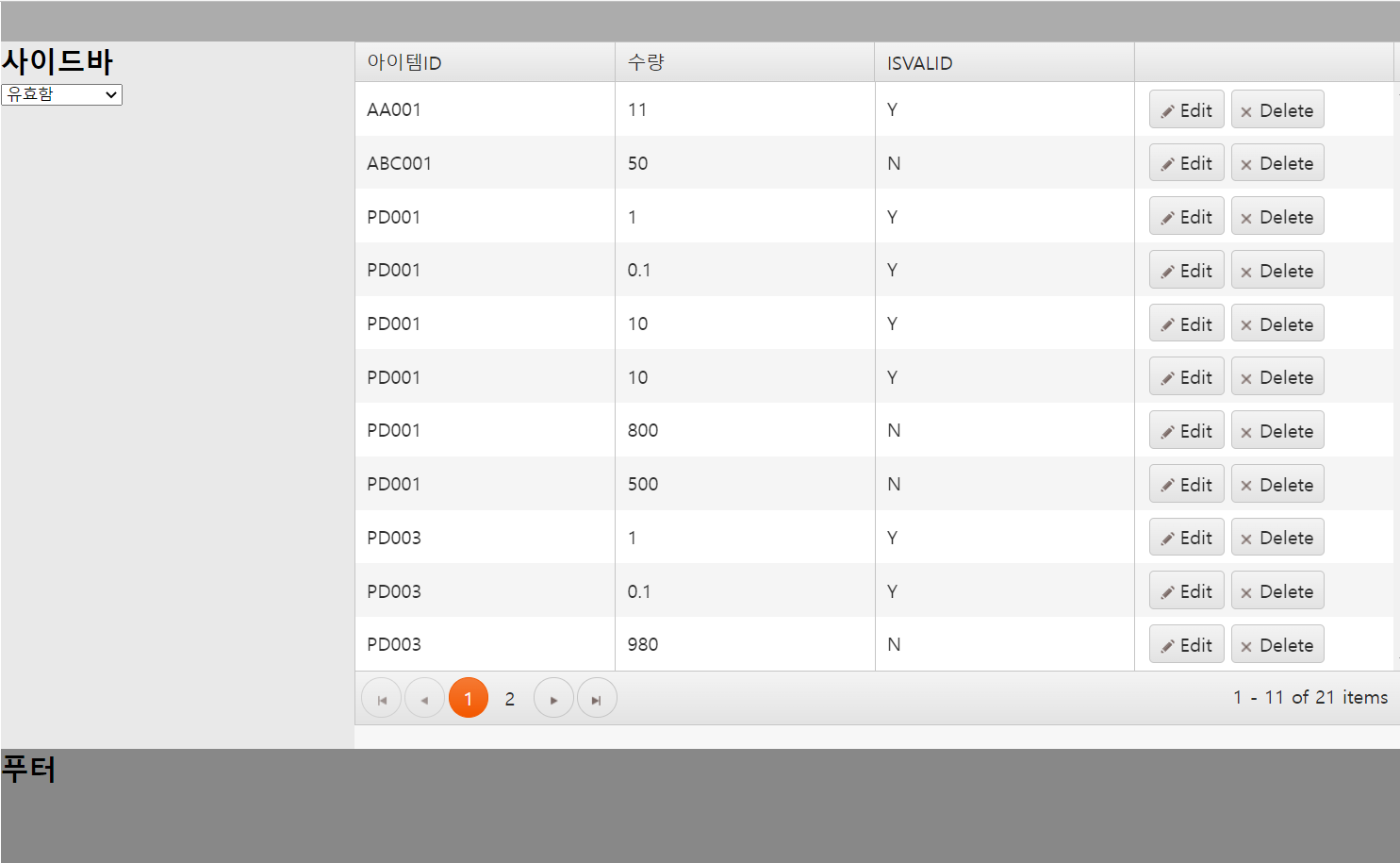
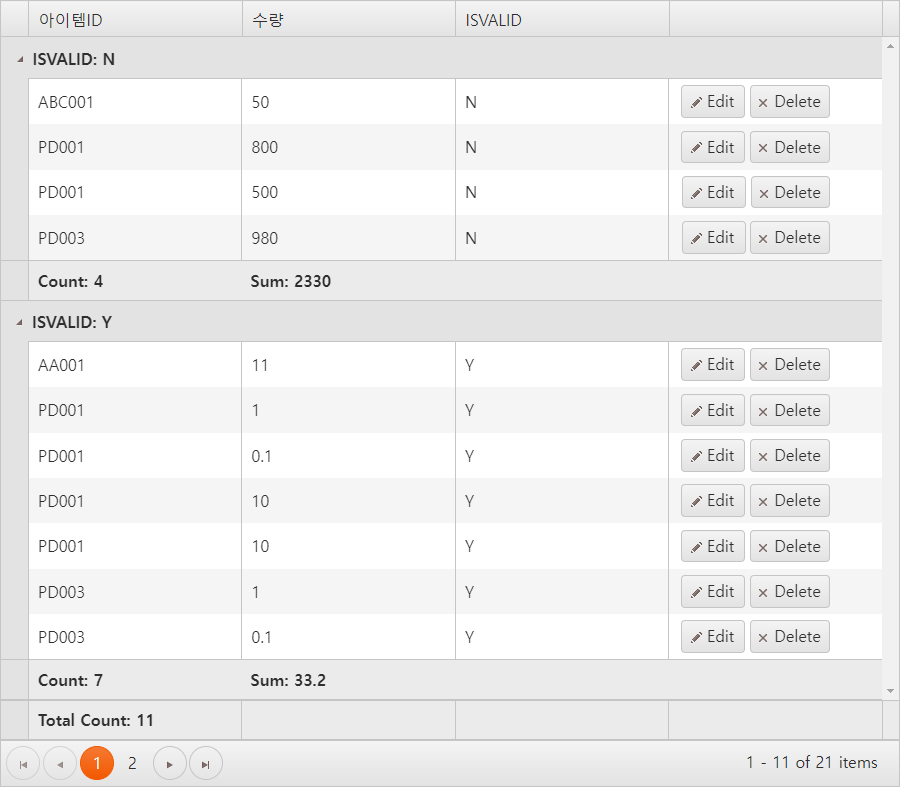
groups를 이용하여 아래 이미지와 같이 테이블을 ISVALID 속성의 값이 N인지 Y인지로 그룹을 만들었습니다.
위와 같이 사용하기 위한 코드를 설명하겠습니다. 우선 스키마 밖에서 그룹을 만들 때 구분 지어줄 필드를 지정합니다.
group: [{ field: "ISVALID" }]
저는 그룹을 지어줄 필드로 ISVALID를 선택했습니다.그리고 스키마 안에서 serverGrouping, groups 필드에 아래 코드 블록의 값을 넣으면 됩니다.
serverGrouping: true,
groups: "groups"
해당 설정이 끝나면 위 이미지처럼 ISVALID로 그룹화된 테이블을 확인할 수 있습니다.
schema.data
데이터 항목이 포함된 서버 응답 필드. 응답에 대한 데이터 항목을 반환하기 위해 호출되는 함수로 설정할 수 있다고 공식 문서에 나와있습니다.
해당 함수는 현재 아래와 같이 사용하고 있습니다.
data: "Data"
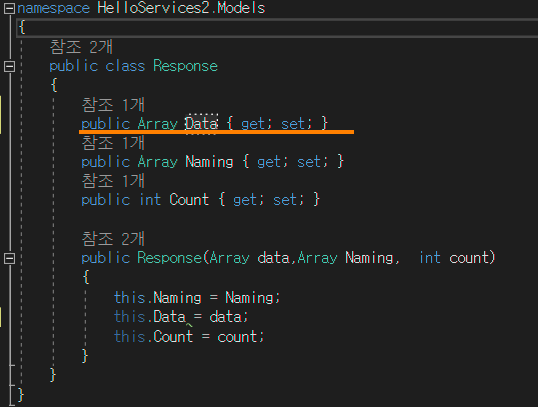
data에 "Data"라고 값을 할당해주는 이유는 서버 측 Response에 그리드에 표시에줄 값들이 있는 변수 를 매핑해주는 것입니다. 서버측의 리턴 타입을 보면 아래와 같습니다.
Resoponse라는 클래스에 Data라는 변수에 그리드에 표기할 값들을 담아 클라이언트에 전달합니다.
Response값에 그리드에 표기할 값만 담는다면 위와같이 매핑 할 필요가 없지만 Response에 여러 변수를 사용한다면 매핑해주어야 합니다.
schema.total
총 데이터 항목 수를 포함하는 서버 응답의 필드. 응답에 대한 총 데이터 항목 수를 반환하기 위해 호출되는 함수로 설정할 수 있습니다.
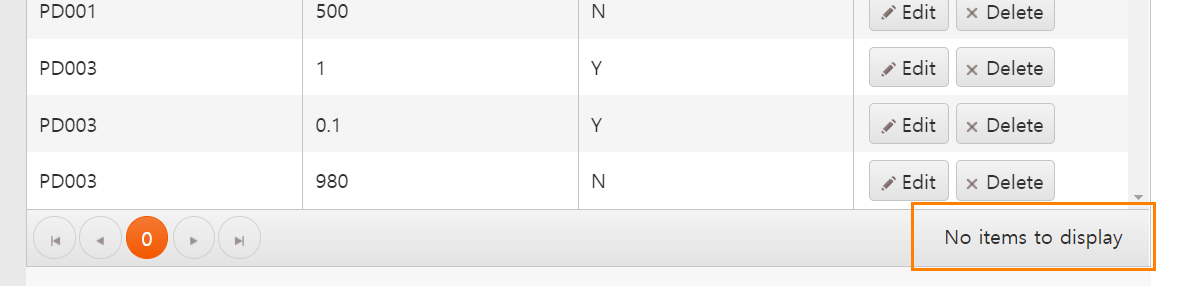
스키마에 total 속성을 지정하지 않은 경우
스키마에 total 속성을 total: "Count"와 같이 지정한 경우 아이템의 인덱스와 총계수를 페이지 우측 하단에 나타냅니다.
schema.parse
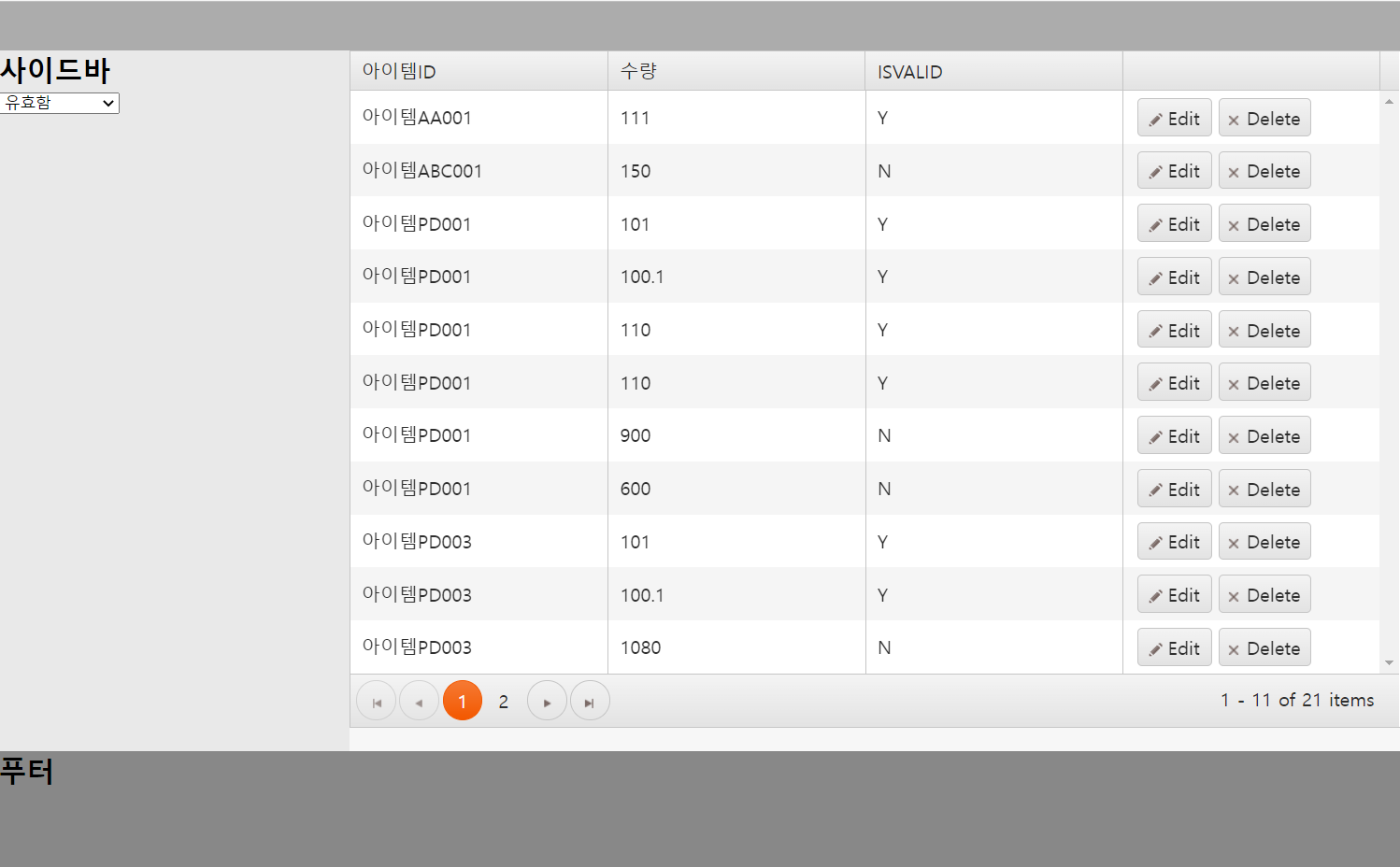
서버 응답을 parse 에서 사전 처리하거나 구문 분석할 때 사용합니다. 해당 기능을 사용한 예시를 보여드리겠습니다. 아래 화면은 parse를 사용하기 전입니다. 저는 parse 기능을 사용해서 아이템 ID 값들에 아이템을 붙이고 수량은 각 수량마다 100을 더하여 보겠습니다.
아래 화면은 제가 원하는 것을 구현한 화면입니다. 아이템 ID에는 각 아이템 ID마다 아이템이라고 붙어있고 수량은
100씩 증가한 것을 확인할 수 있습니다.
서버의 데이터를 사용하기 전 파싱 하기 위해 사용한 함수는 아래와 같습니다.
parse: function (response) {
var boms = [];
for (var i = 0; i < response.Data.length; i++) {
var bom = {
ITEMID: "아이템" + response.Data[i].ITEMID,
ISVALID: response.Data[i].ISVALID,
QTY: response.Data[i].QTY + 100
};
boms.push(bom);
}
response.Data = boms;
return response;
}
위와 같이 사용하기 위해서 파라미터 response 가 어떤 식으로 메서드로 들어오는지 확인하여야 합니다.
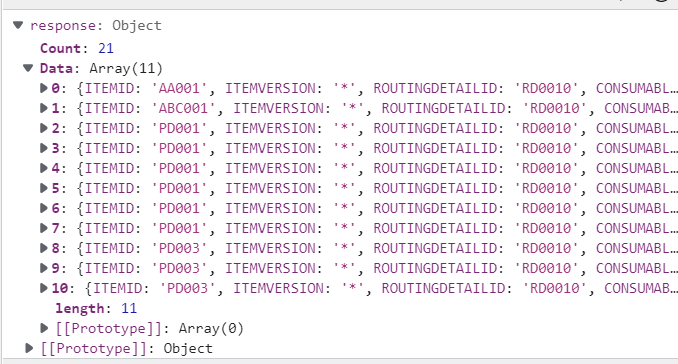
response 파라미터 값을 확인하기 위해 디버깅에 있는 조사식을 활용하였습니다.
위와 같이 ITEMID와, QTY 등의 값은 response의 data에 array형식으로 들어가 있음으로 response.Data 와 같은 형식으로 값에 접근할 수 있습니다.
schema.model
모델 객체를 통해서 속성의 자료형을 변경하거나 밸리데이션 체크 등의 기능을 수행할 수 있습니다.
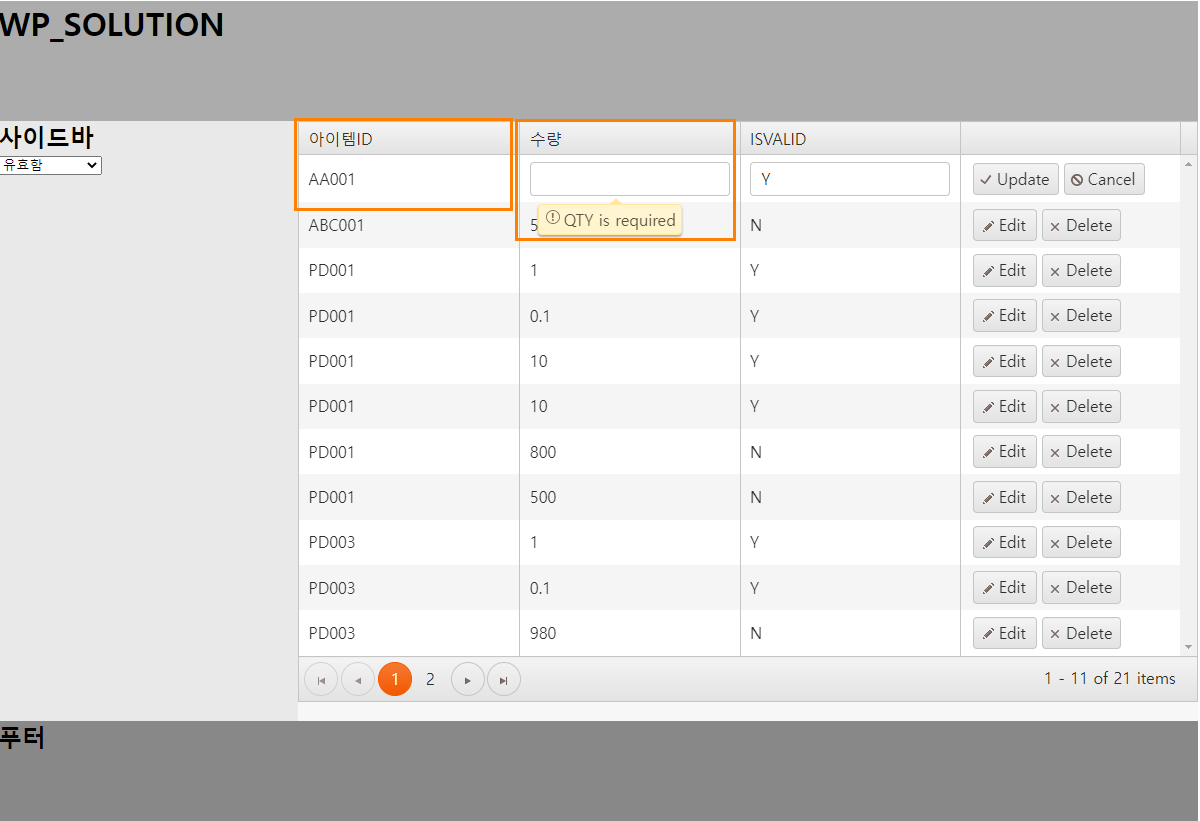
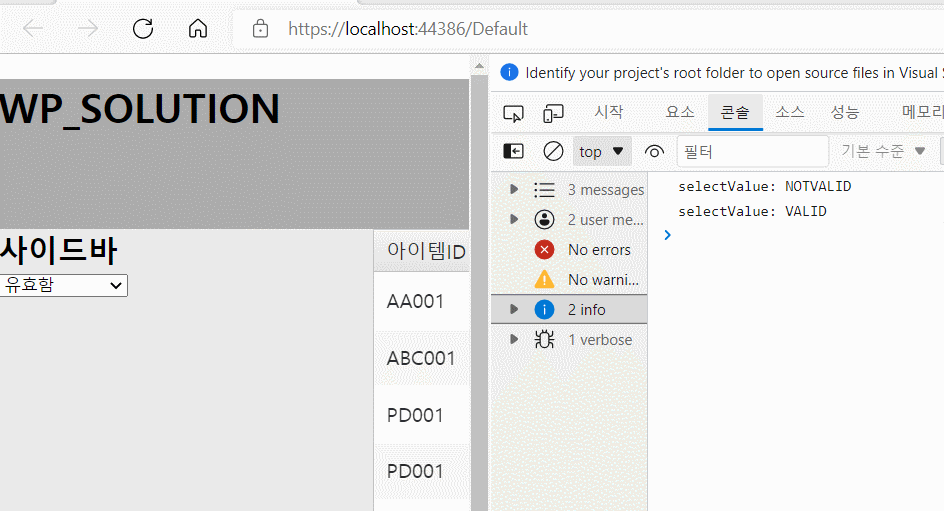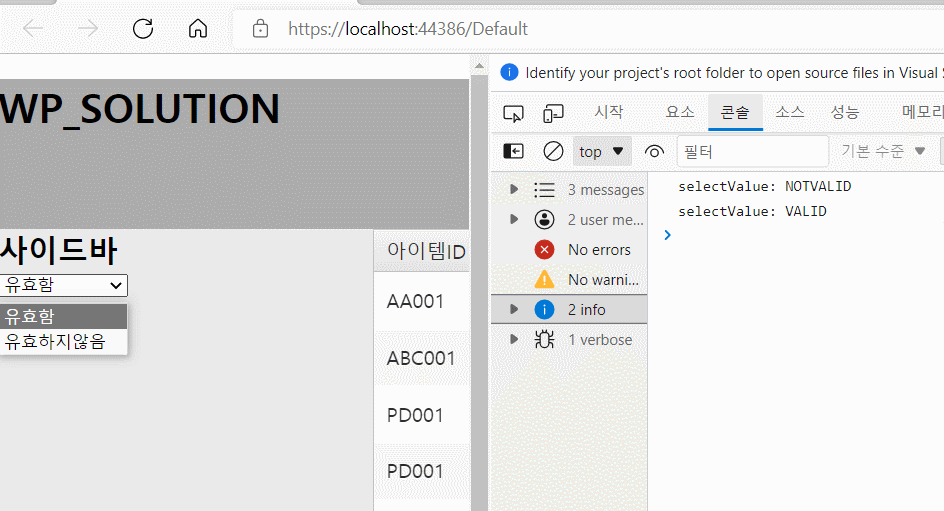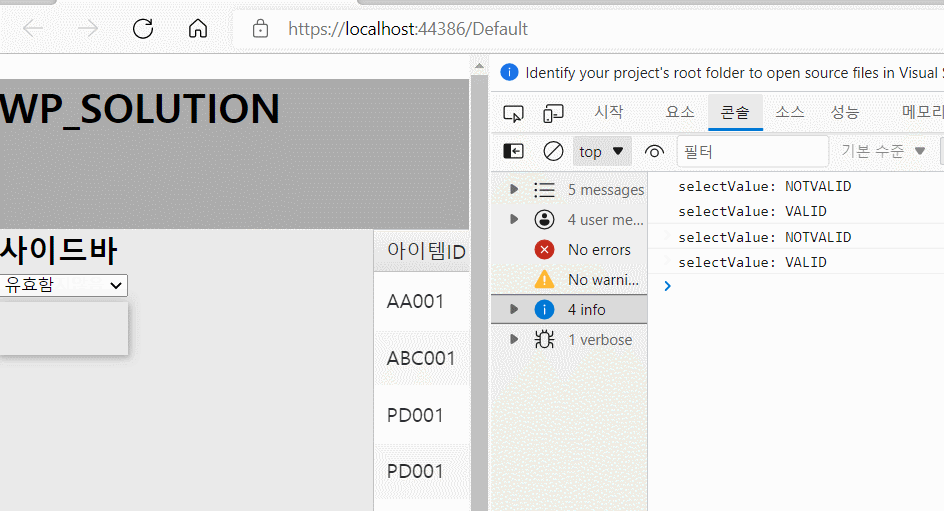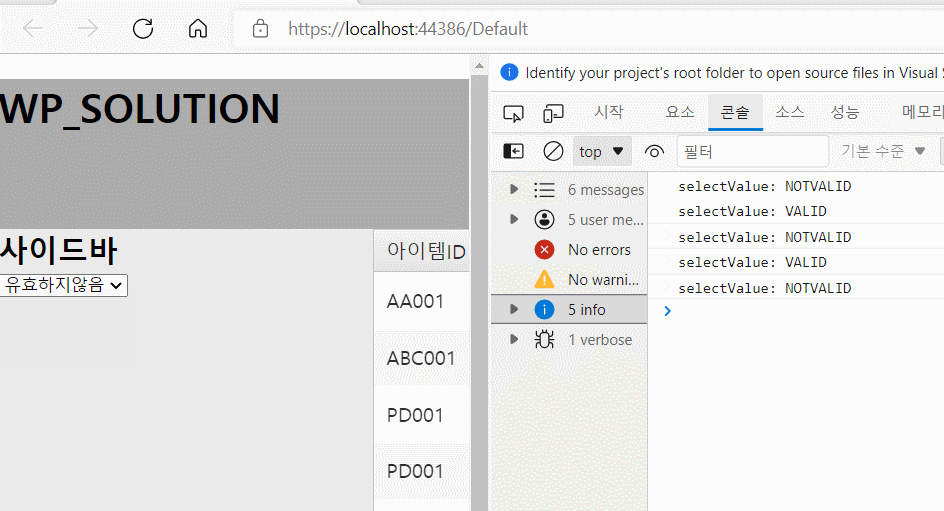
예를 들어 ID 값을 사용자가 함부로 바꾸면 여러 가지 문제가 발생할 수 있습니다. 따라서 아래와 같이 해당 필드의 edit 여부를 허용해줄지 설정해줄 수 있으며 데이터의 올바른 입력을 위해서 validation check도 할 수 있습니다.
- 아이템ID의 경우 editable 값을 False로 할당하였기 때문에 편집이 되지 않아야 됩니다. 따라서 위 화면처럼 편집이 불가능하게 됩니다.
- QTY와 같은 경우 required값을 True로 주었습니다. 따라서 위와같이 공백을 입력할 경우 경고창이 나타나게 됩니다.
ex2
model: {
id: "ProductID",
fields: {
ProductID: {
//this field will not be editable (default value is true)
editable: false,
// a defaultValue will not be assigned (default value is false)
nullable: true
},
ProductName: {
//set validation rules
validation: { required: true }
},
UnitPrice: {
//data type of the field {number|string|boolean|date} default is string
type: "number",
// used when new model is created
defaultValue: 42,
validation: { required: true, min: 1 }
}
}
}
2번째 예제는 공식문서의 예제입니다. 해당 예제를 통해 알수있는 점은 지정한 속성의 type과 기본 값 그리고 벨리데이션을 설정해줄 수 있습니다.
schema.aggregates
테이블의 원하는 속성을 선택해서 집계 함수를 적용하고 해당 결과를 Json 형태로 리턴해주는 객체입니다.
aggregate를 사용하려면 serverAggregates 값을 true로 바꿔주어야 됩니다.
schema: {
data: "items",
errors: function(response) {
/* The result can be observed in the DevTools(F12) console of the browser. */
console.log("errors as function", response.errors[0])
return response.errors;
}
}
오늘은 백준 문제 중 1325번 효율적인 해킹 문제를 해결해보았다. 해당 문제는 한번의 해킹으로 최대한 많은 컴퓨터를 해킹하기를 원한다. 각 컴퓨터는 신뢰 관계가 있는데 만약 신용 받는 컴퓨터를 해킹하면 신용하는 컴퓨터는 자동으로 해킹이 된다.
해당 문제의 특징은 그래프가 일반 그래프가 아니라는 점과 한번에 가장 많은 수의 컴퓨터를 해킹할 수 있는 컴퓨터의 번호를 오름차순으로 리턴해주어야 한다는 특징이 있다.
from collections import deque
n, m = map(int, input().split())
adj = [[] for _ in range(n+1)]
for _ in range(m):
x, y = map(int, input().split())
adj[y].append(x)
def bfs(v):
q = deque([v])
visited = [False] * (n+1)
visited[v] = True
count = 1
while q:
v = q.popleft()
for e in adj[v]:
if not visited[e]:
q.append(e)
visited[e] = True
count += 1
return count
result = []
max_value = -1
for i in range(1, n+1):
c = bfs(i)
if c > max_value:
result = [i]
max_value = c
elif c == max_value:
result.append(i)
max_value = c
for e in result:
print(e, end=" ")
db 연결은 LINQ to SQL 클래스를 사용했고 해당 부분은 동영상을 참조하면 될 것이다.
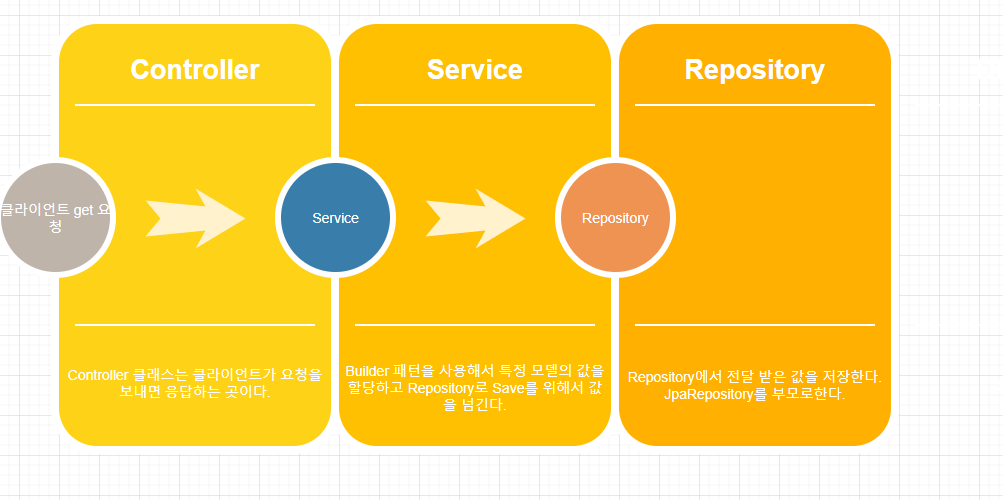
이글에서는 GRID를 사용하기 위해서 Controller 단과 클라이언트 html 파일 위주로 정리하겠다.
public class WM_BILLOFMATERIAL_CONTROLLER : ApiController
{
private Data.NorthwindContextDataContext _context = new Data.NorthwindContextDataContext();
HttpRequest _request = HttpContext.Current.Request;
public Models.Response Get()
{
int take = _request["take"] == null ? 10 : int.Parse(_request["take"]);
int skip = _request["skip"] == null ? 0 : int.Parse(_request["skip"]);
var bom = (from b in _context.WM_BILLOFMATERIAL
select new Models.WM_BILLOFMATERIAL(b)).Skip(skip).Take(take).ToArray();
return new Models.Response(bom, _context.WM_BILLOFMATERIAL.Count());
}
public HttpResponseMessage Post()
{
var response = new HttpResponseMessage();
try
{
var bom_update = (from bom in _context.WM_BILLOFMATERIAL
where bom.ITEMID == _request["ITEMID"]
select bom).FirstOrDefault();
if (bom_update != null)
{
bom_update.QTY = _request["QTY"] == null ? bom_update.QTY : Convert.ToDecimal(_request["QTY"]);
_context.SubmitChanges();
}
else
{
response.StatusCode = System.Net.HttpStatusCode.InternalServerError;
response.Content = new StringContent(string.Format("the Item with itemId {0} was not found in the database"));
}
return response;
}catch (Exception ex)
{
response.StatusCode = System.Net.HttpStatusCode.InternalServerError;
response.Content = new StringContent(string.Format("there was an error updating bom"));
return response;
}
}
}
위 컨트롤러에는 Get 메서드와 Post 메서드가 있다.
해당 메소드들을 통해 Get 요청과 Post 요청을 처리한다.
뭔가 매핑을 하지않아도 메서드 이름을 Get, Post로 정한 다음에 사용하기만 해도 처리가 된다.
Controller가 수행되는 순서에 대해 정리해보겠다.
클라이언트에서 Controller로 get, post 등의 요청을 하면 제일 먼저 클래스 가장 위의 Data.NorthwindContextDataContext _context가 가장 먼저 실행되고 다음으로
HttpRequest _request = HttpContext.Current.Request 가 실행되었다.
해당 변수들은 생성자에 들어가있지도 않은데 디버깅 포인트가 해당 포인트에서 가장 먼저 잡히는 것이 이해가 잘 안 되었다. 그래서 NorthwindContextDataContext를 Ctrl + 우클릭으로 타고 들어가 보니 mapping이란 키워드가 들어간 변수가 있었다. 아마 자동으로 매핑해주기 위해서 생성된 클래스 같다.
다음 순서로 URL 경로가 맞다면 해당 요청에 해당되는 POST 또는 GET 메소드가 실행된다.
GET 메소드의 경우 아래와 같이 구현되어있다. 우선 핵심인 LINQ가 사용된 부분을 보자면
in 뒤에있는뒤에 있는 클래스들 통해 값을 받고 from 뒤에 있는 변수 이름에 값을 넣고 select를 통해서 값을 표현할 방식을 정한다. 그다음 take과 skip은 kendo grid에서 갑을 한 번에 얼마나 가지고 올지를 정하는 부분이다. 그리고 데이터를 성공적으로 가져왔다면 Models 클래스에 있는 Response에 해당 값을 담아서 클라이언트로 반환을 해준다. 아래 코드를 통해 말하자면 한 페이지에 10개의 행을 나타내겠다는 의미이다.
public Models.Response Get()
{
int take = _request["take"] == null ? 10 : int.Parse(_request["take"]);
int skip = _request["skip"] == null ? 0 : int.Parse(_request["skip"]);
var bom = (from b in _context.WM_BILLOFMATERIAL
select new Models.WM_BILLOFMATERIAL(b)).Skip(skip).Take(take).ToArray();
return new Models.Response(bom, _context.WM_BILLOFMATERIAL.Count());
}
다음으로 Post 메소드를 살펴보겠다. Post 메서드는 아래와 같이 구현되어있다.
public HttpResponseMessage Post()
{
var response = new HttpResponseMessage();
try
{
var bom_update = (from bom in _context.WM_BILLOFMATERIAL
where bom.ITEMID == _request["ITEMID"]
select bom).FirstOrDefault();
if (bom_update != null)
{
bom_update.QTY = _request["QTY"] == null ? bom_update.QTY : Convert.ToDecimal(_request["QTY"]);
_context.SubmitChanges();
}
else
{
response.StatusCode = System.Net.HttpStatusCode.InternalServerError;
response.Content = new StringContent(string.Format("the Item with itemId {0} was not found in the database"));
}
return response;
}catch (Exception ex)
{
response.StatusCode = System.Net.HttpStatusCode.InternalServerError;
response.Content = new StringContent(string.Format("there was an error updating bom"));
return response;
}
}
위 포스트 메서드는 사용자가 웹 화면에서 특정 아이템의 재고량을 변화시킬 때 사용되는 메서드이다. 사용자가 특정 아이템의 재고량을 수정하고 업데이트 버튼을 클릭하면 수행된다. 사용자가 입력한 값이 만약에 null이라면 업데이트하지 않도록 하거나 에러가 발생하게 되면 처리해주는 로직이 추가되어 있다.
다음으로 Default.aspx를 살펴보겠다. 해당 파일은 사용자가 사용할 UI 단 웹이다. 해당 파일 중 script 부분을
집중적으로 분석해보겠다.
<script>
$(function () {
$("#employeesGrid").kendoGrid({
columns: [
{ field: "ITEMID", title: "아이템ID" },
{ field: "QTY", title: "수량" },
"ISVALID",
{ command: ["edit", "destroy"], title: ""}
],
sortable: true,
pageable: true,
// editable: true,
editable: "inline",
dataSource: new kendo.data.DataSource({
transport: {
read: "api/WM_BILLOFMATERIAL_",
update: {
url: function (WM_BILLOFMATERIAL) {
//return "api/WM_BILLOFMATERIAL_/" + WM_BILLOFMATERIAL.ITEMID
return "api/WM_BILLOFMATERIAL_/" + WM_BILLOFMATERIAL.ITEMID
},
type: "POST"
}
},
pageSize: 15,
serverPaging: true,
schema: {
// the array of repeating data elements (employees)
data: "Data",
// the total count of records in the whole dataset. used
// for paging
total: "Count",
model: {
id: "ITEMID",
fields: {
ITEMID: { editable: false , nullable: false },
QTY: { validation: { required: true }, nullable: false },
ISVALID: { validation: { required: true }, nullable: false }
}
}
}
})
});
});
</script>
위 스크립트 태그 안에 있는 내용은 전부 하나의 kendoGrid를 위한 기능이다. 해당 함수의 기능을 위에서부터 아래로 살펴보도록 하겠다.
columns
가장 위에 있는 columns에는 columns 이름 그대로 kendoGrid에서 나타나게 될 속성들의 모임이다. 만약에 속성 이름 그대로 안 쓰고 다른 이름을 쓰고 싶다면 { filed: "ITEMID", title: "아이템 ID" }라고 쓰면 되고 속성 이름을 변경 없이 그대로 사용하고 싶으면 "ISVALID" 그냥 속성 이름을 문자열 형태로 주면 된다.
sortable
위 sotable 변수에 true 값을 넣어주게 되면 속성 이름을 클릭할 수 있게 되는데 클릭을 하면 해당 속성 값을 기준으로 그리드의 행들이 정렬 되게 된다.
pageable
그리드의 모든 속성을 보여주지 않고 한 페이지에 해당되는 행의 수만큼 표현해서 보여주는 설정을 할 수 있도록 한다.
editable
편집을 가능하게 한다. true나 혹은 inline 값을 할당할 수 있었는데 true를 넣게 되면 속성 개별로 값을 할당할 수 있고 inline 값을 넣으면 한 행씩 편집할 수 있도록 한다.
import sys
sys.setrecursionlimit(100000)
def dfs(x,y):
visited[x][y] = True
directions = [(-1,0),(1,0), (0,-1), (0,1)]
for dx, dy in directions:
nx, ny = x + dx, y + dy
if nx < 0 or nx >= n or ny < 0 or ny >= m:
continue
if array[nx][ny] and not visited[nx][ny]:
dfs(nx,ny)
for _ in range(int(input())):
m, n, k = map(int, input().split())
array = [[0] * m for _ in range(n)]
visited = [[False] * m for _ in range(n)]
for _ in range(k):
y, x = map(int, input().split())
array[x][y] = 1
result = 0
for i in range(n):
for j in range(m):
if array[i][j] and not visited[i][j]:
dfs(i, j)
result += 1
print(result)
위 코드를 활용해 답을 구하였다. 재밌는 점은 directions 리스트의 하나의 값에 x와 y 좌표를 담아 두었다. 그리고 for문을 돌면서 x,y좌표에 값을 더해서 돌도록 만들엇고 값의 범위가 올바른지 그리고 방문하지 않았던 좌표인지 그리고 벌레가 방문 할 수 있는 좌표인지 검증을 통해 dfs함수를 다시 호출한다. 해당 문제를 풀면서 dfs문제의 핵심이라 해도 될 정도로 중요한 문제라고 느꼈고 가끔식 복습해야겠다