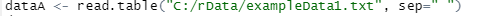dataA <- read.table("C:/rData/exampleData1.txt", sep=" ")
dataA
names(dataA) <- c("gender", "rScore", "pythonScore", "javaScore")
dataA
# 변수 명이 텍스트 파일에 있을 경우 header = TRUE 를 사용해서 번수 이름을 지정한다.
dataB <- read.table("C:/rData/exampleData2.txt", header = TRUE, sep=" ")
dataB
read.csv("C:/rData/exampleData3.txt")
URL="http://archive.ics.uci.edu/ml/machine-learning-databases/cpu-performance/machine.data"
cpuPerformence <- read.table(URL, header = FALSE, sep = ",")
head(cpuPerformence)
gender <- c("M", "F", "M", "F", "F")
rScore <- c(58, 66, 92, 78, 88)
pythonScore <- c(88, 55, 98, 75, 58)
javaScore <- c(66, 88, 90, 78, 66)
dataW <- data.frame(gender, rScore, pythonScore, javaScore)
write.table(dataW, "C:/rData/A.txt", quote=TRUE, row.names=FALSE)
write.table(dataW, "C:/rData/B.txt", quote=FALSE, row.names=FALSE, sep=",")
str(iris)
head(iris)
write.csv(iris, "C:/rData/iris.csv", quote=FALSE, row.names=FALSE)
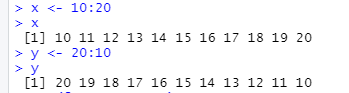
x <- c(1, 3, 5, 7, 9)
y <- c(3, 4, 5, 6, 7)
if(mean(x) == mean(y))
{print("mean(x) is equal to mean(y)")}
if(var(x) > var(y))
{print("var(x) is greater than var(y)")
print(var(x))
print(var (y))}
if(is.vector(x))
{print("x is vector")}else
{print("x is not vector")}
signal <- function(light){
if(light == "red")
{print('정지')}else if(light=="green")
{print("직진")}else
{print("몰름")}
}
light <- "red"
signal(light)
jumsu <- c(99, 20, 60, 80, 70)
grade <- ifelse(jumsu >= 60, "Pass", "Fail")
data.frame(jumsu, grade)
score <- c(1, 2, 3, 4, 5)
a <- 2
switch(a, "1"=mean(score), "2"=sum(score), "3"=var(score))
evenSum <- 0
oddSum <- 0
for(x in 1:100)
if(x %% 2 == 0) {
evenSum <- evenSum + x
} else {
oddSum <- oddSum + x
}
print(evenSum)
print(oddSum)
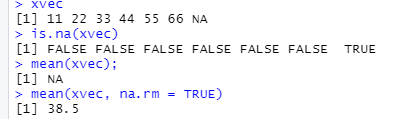
data <- c(1, NA, NA, 2, 3, 4, 5, NA, 6, 7, 8, NA, 9, 10, NA)
completeData <- c()
for(x in data)
if(!is.na(x)) {
completeData <- c(completeData, x)
} else {
next
}
print(completeData)
print(length(completeData))
data <- c(1, NA, NA, 2, 3, 4, 5, NA, 6, 7, 8, NA, 9, 10, NA)
for(x in 1:length(data)) {
if(is.na(data[x])) data[x] <-0
}
print(data)
print(length(data))
print(mean(data))
gugudan <- function(dan){
i=1
while (i<=9) {
guguDan <- i*dan
print(guguDan)
i = i+1
}
}
gugudan(2)
sum <- 0
i <- 0
repeat{
sum <- sum+i
if(sum >= 3000)
break
i <- i+1
}
print(i)
print(sum)