오류
source release 11 requires target release 11
해당 오류는 JDK 버전 오류이다.
해당 오류 발생시 확인해야하는 사항이 있다.
1. build.gradle 파일에서 sourceCompatibility = '11' 인지 확인한다.
2. ProjectStructure > ProjectSettings > Project
- ProjectSDK = 11
- Project language level = 11

글쓴이의 경우 1.8 버전이 default로 되있어서 오류가 난 것이었다.
3. Project Structure > Plaform Settings > SDKs
- SDK 버전이 설치 되어있는지 확인한다.
참고 글
https://hothoony.tistory.com/1105
[intellij] java: warning: source release 11 requires target release 11
오류 java: warning: source release 11 requires target release 11 오류 발생시 확인해 볼 내용 build.gradle sourceCompatibility = '11' Project Structure > Project Settings > Project Project SDK = 11 P..
hothoony.tistory.com
'오늘만난오류' 카테고리의 다른 글
| Unterminated string (0) | 2022.03.21 |
|---|---|
| 외래키 설정 오류 collation & SQL Error [1452] [23000]: (conn=3205) Cannot add or update a child row: a foreign key constraint fails (0) | 2022.03.14 |
| Fail : 문자열을 날짜 및/또는 시간으로 변환하지 못했습니다. (0) | 2022.01.10 |
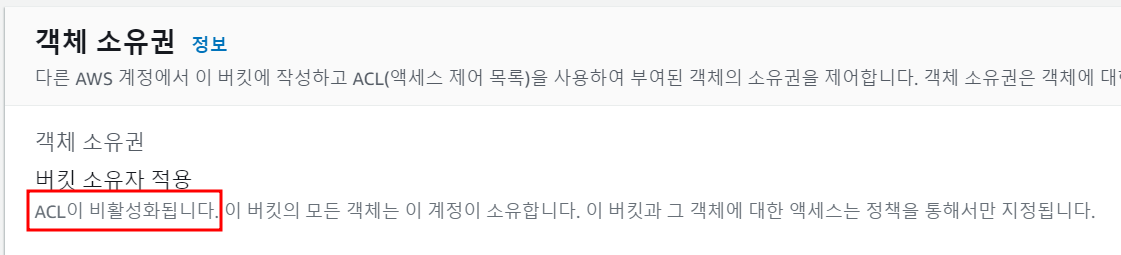
| The bucket does not allow ACLs (0) | 2022.01.08 |
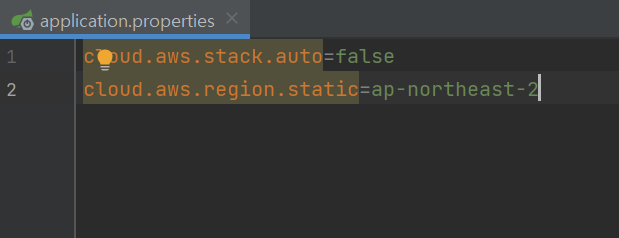
| Cannot resolve reference to bean 'amazonS3' while setting constructor argument (0) | 2022.01.08 |