kendoGrid를 위해 사용되는 schema와 schema는 어떤 기능이 있는지 살펴보겠습니다.
schema
서버에서 보낸 응답을 파싱 하여 KendoGrid에 어떻게 데이터를 보여줄지 그리고 편집은 어떻게 할지 알려 줍니다.
schema.groups
그룹을 포함하는 서버 응답의 필드 응답에서 그룹을 반환하기 위해 호출되는 함수로 설정할 수 있습니다.
해당 옵션은 serverGrouping option에 true 값을 할당해야 사용할 수 있습니다.
위 내용은 공식 문서를 번역한 설명입니다. 내용이 조금 어려우니 아래 예시를 참조해주세요
직접 사용한 예를 보여드리겠습니다.
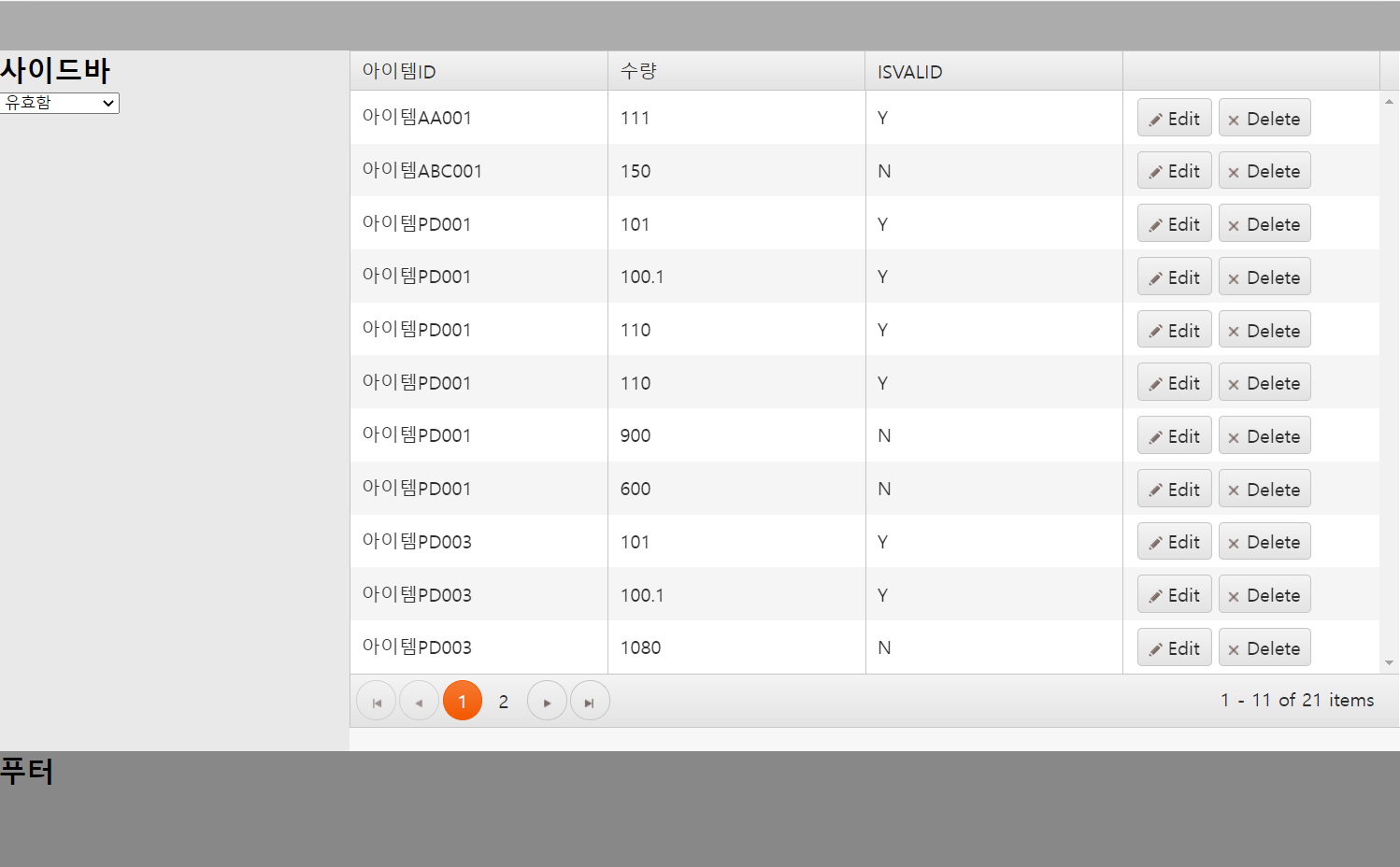
groups를 이용하여 아래 이미지와 같이 테이블을 ISVALID 속성의 값이 N인지 Y인지로 그룹을 만들었습니다.
위와 같이 사용하기 위한 코드를 설명하겠습니다. 우선 스키마 밖에서 그룹을 만들 때 구분 지어줄 필드를 지정합니다.
group: [{ field: "ISVALID" }]
저는 그룹을 지어줄 필드로 ISVALID를 선택했습니다.그리고 스키마 안에서 serverGrouping, groups 필드에 아래 코드 블록의 값을 넣으면 됩니다.
serverGrouping: true,
groups: "groups"
해당 설정이 끝나면 위 이미지처럼 ISVALID로 그룹화된 테이블을 확인할 수 있습니다.
schema.data
데이터 항목이 포함된 서버 응답 필드. 응답에 대한 데이터 항목을 반환하기 위해 호출되는 함수로 설정할 수 있다고 공식 문서에 나와있습니다.
해당 함수는 현재 아래와 같이 사용하고 있습니다.
data: "Data"
data에 "Data"라고 값을 할당해주는 이유는 서버 측 Response에 그리드에 표시에줄 값들이 있는 변수 를 매핑해주는 것입니다. 서버측의 리턴 타입을 보면 아래와 같습니다.
Resoponse라는 클래스에 Data라는 변수에 그리드에 표기할 값들을 담아 클라이언트에 전달합니다.
Response값에 그리드에 표기할 값만 담는다면 위와같이 매핑 할 필요가 없지만 Response에 여러 변수를 사용한다면 매핑해주어야 합니다.
schema.total
총 데이터 항목 수를 포함하는 서버 응답의 필드. 응답에 대한 총 데이터 항목 수를 반환하기 위해 호출되는 함수로 설정할 수 있습니다.
스키마에 total 속성을 지정하지 않은 경우
스키마에 total 속성을 total: "Count"와 같이 지정한 경우 아이템의 인덱스와 총계수를 페이지 우측 하단에 나타냅니다.
schema.parse
서버 응답을 parse 에서 사전 처리하거나 구문 분석할 때 사용합니다. 해당 기능을 사용한 예시를 보여드리겠습니다. 아래 화면은 parse를 사용하기 전입니다. 저는 parse 기능을 사용해서 아이템 ID 값들에 아이템을 붙이고 수량은 각 수량마다 100을 더하여 보겠습니다.
아래 화면은 제가 원하는 것을 구현한 화면입니다. 아이템 ID에는 각 아이템 ID마다 아이템이라고 붙어있고 수량은
100씩 증가한 것을 확인할 수 있습니다.
서버의 데이터를 사용하기 전 파싱 하기 위해 사용한 함수는 아래와 같습니다.
parse: function (response) {
var boms = [];
for (var i = 0; i < response.Data.length; i++) {
var bom = {
ITEMID: "아이템" + response.Data[i].ITEMID,
ISVALID: response.Data[i].ISVALID,
QTY: response.Data[i].QTY + 100
};
boms.push(bom);
}
response.Data = boms;
return response;
}
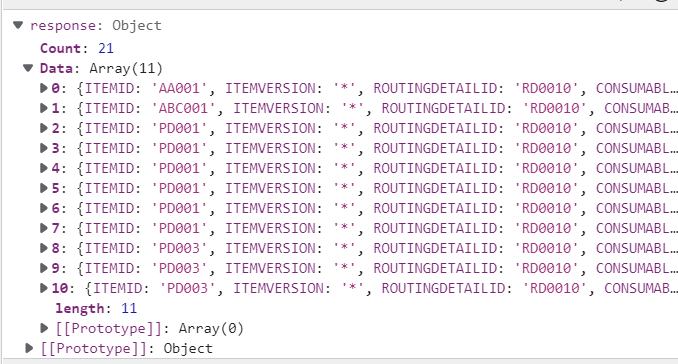
위와 같이 사용하기 위해서 파라미터 response 가 어떤 식으로 메서드로 들어오는지 확인하여야 합니다.
response 파라미터 값을 확인하기 위해 디버깅에 있는 조사식을 활용하였습니다.
위와 같이 ITEMID와, QTY 등의 값은 response의 data에 array형식으로 들어가 있음으로 response.Data 와 같은 형식으로 값에 접근할 수 있습니다.
schema.model
모델 객체를 통해서 속성의 자료형을 변경하거나 밸리데이션 체크 등의 기능을 수행할 수 있습니다.
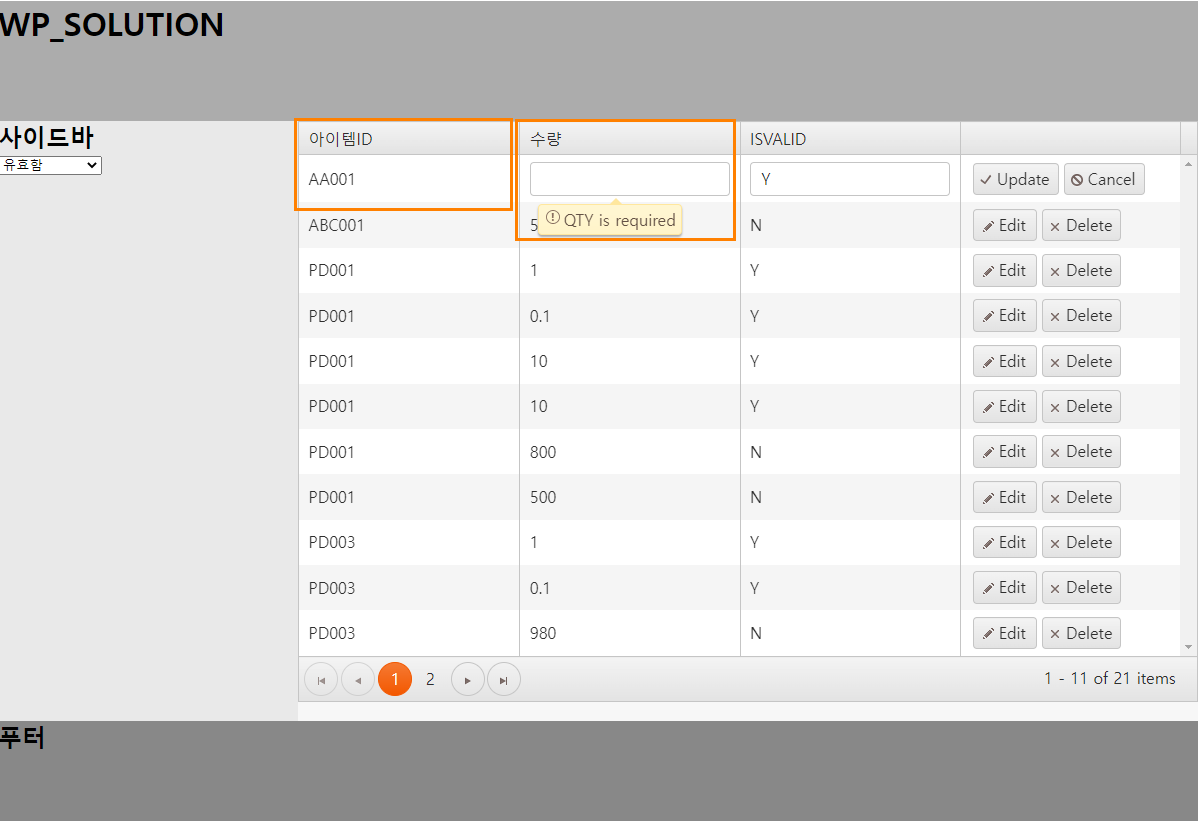
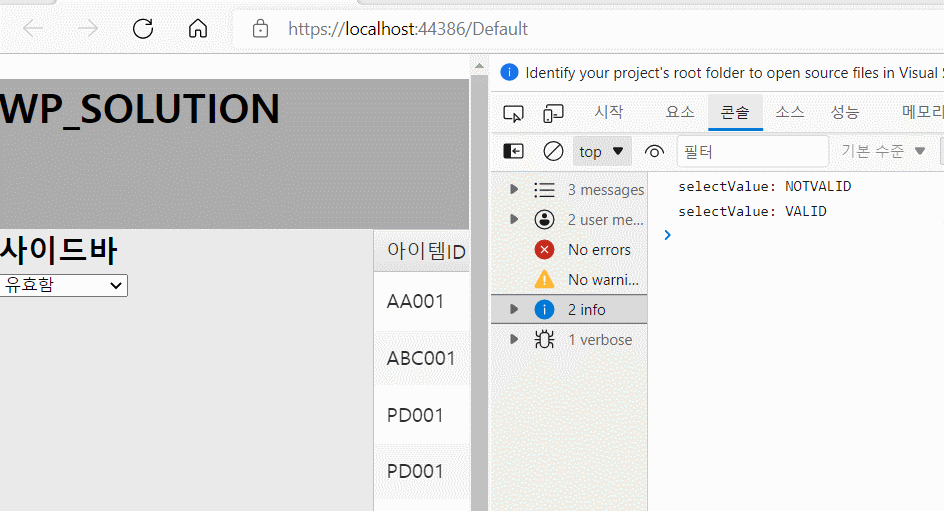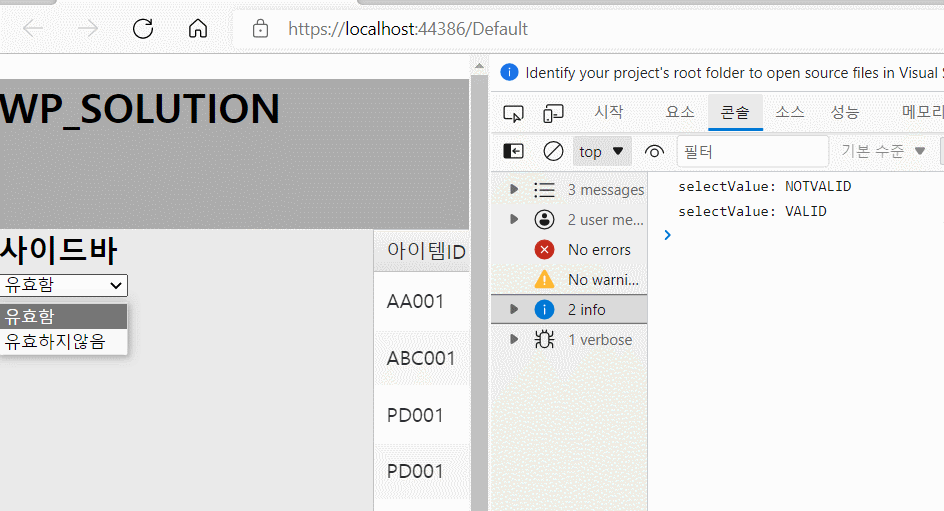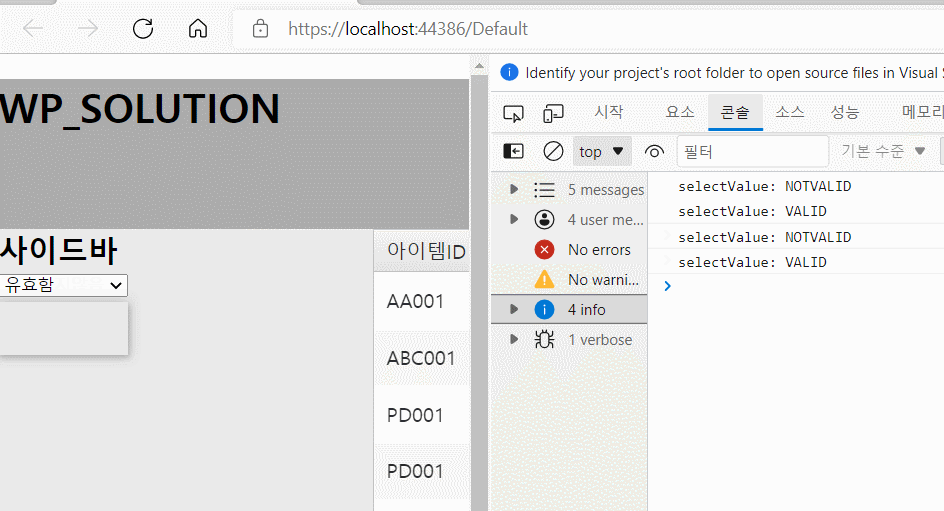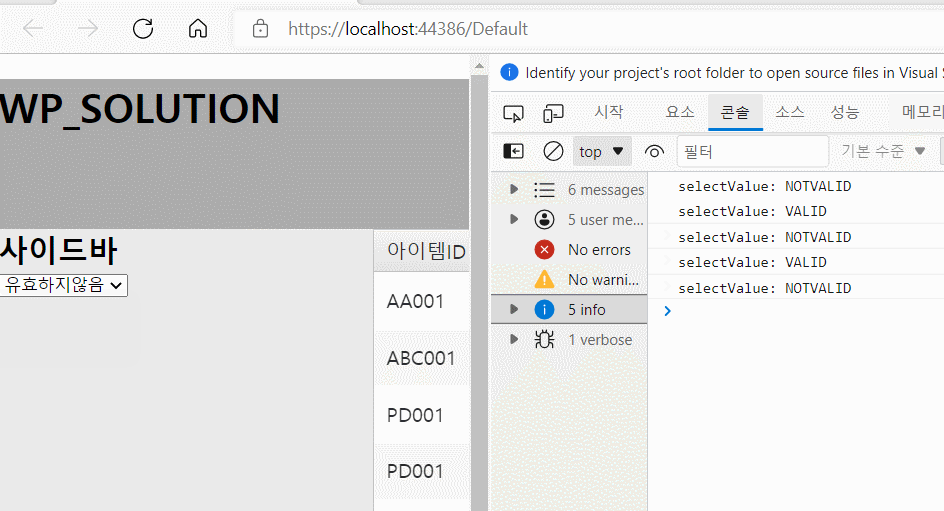
예를 들어 ID 값을 사용자가 함부로 바꾸면 여러 가지 문제가 발생할 수 있습니다. 따라서 아래와 같이 해당 필드의 edit 여부를 허용해줄지 설정해줄 수 있으며 데이터의 올바른 입력을 위해서 validation check도 할 수 있습니다.
- 아이템ID의 경우 editable 값을 False로 할당하였기 때문에 편집이 되지 않아야 됩니다. 따라서 위 화면처럼 편집이 불가능하게 됩니다.
- QTY와 같은 경우 required값을 True로 주었습니다. 따라서 위와같이 공백을 입력할 경우 경고창이 나타나게 됩니다.
ex2
model: {
id: "ProductID",
fields: {
ProductID: {
//this field will not be editable (default value is true)editable: false,
// a defaultValue will not be assigned (default value is false)nullable: true
},
ProductName: {
//set validation rulesvalidation: { required: true }
},
UnitPrice: {
//data type of the field {number|string|boolean|date} default is stringtype: "number",
// used when new model is createddefaultValue: 42,
validation: { required: true, min: 1 }
}
}
}
2번째 예제는 공식문서의 예제입니다. 해당 예제를 통해 알수있는 점은 지정한 속성의 type과 기본 값 그리고 벨리데이션을 설정해줄 수 있습니다.
schema.aggregates
테이블의 원하는 속성을 선택해서 집계 함수를 적용하고 해당 결과를 Json 형태로 리턴해주는 객체입니다.
aggregate를 사용하려면 serverAggregates 값을 true로 바꿔주어야 됩니다.
schema: {
data: "items",
errors: function(response) {
/* The result can be observed in the DevTools(F12) console of the browser. */console.log("errors as function", response.errors[0])
return response.errors;
}
}